🦄 How to build a State-of-the-Art Conversational AI
on
How to build a State-of-the-Art Conversational AI with Transfer Learning
이 글은 ConvAI2 NeurIPS(2018) 대회에서 SOTA(state-of-the-art)를 기록한 Hugging Face 의 Conversation AI에 대한 튜토리얼를 번역한 포스트입니다. 졸업 프로젝트를 진행하는 학부생 수준에서 작성한 글이니 참고하고 봐주시면 감사하겠습니다.😃
다음 사이트에서 Hugging Face가 제작한 간단한 데모를 체험 해 보실 수 있습니다.🎮convai.huggingface.co.
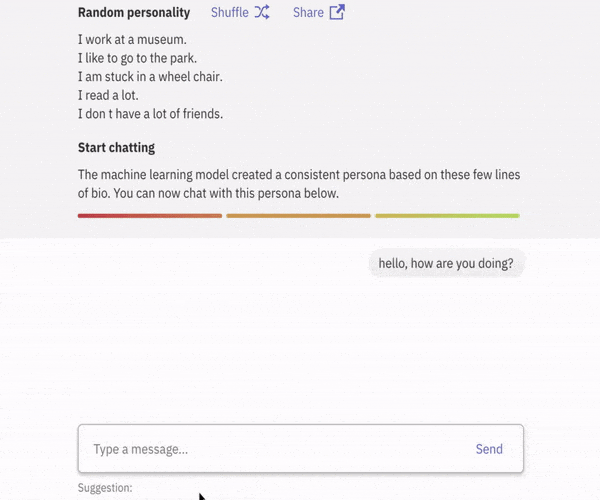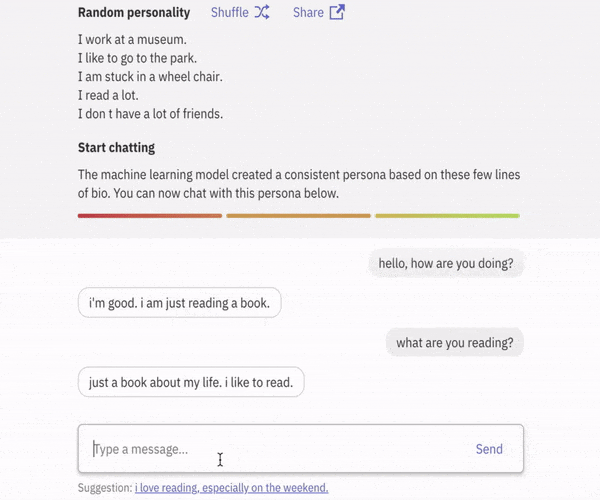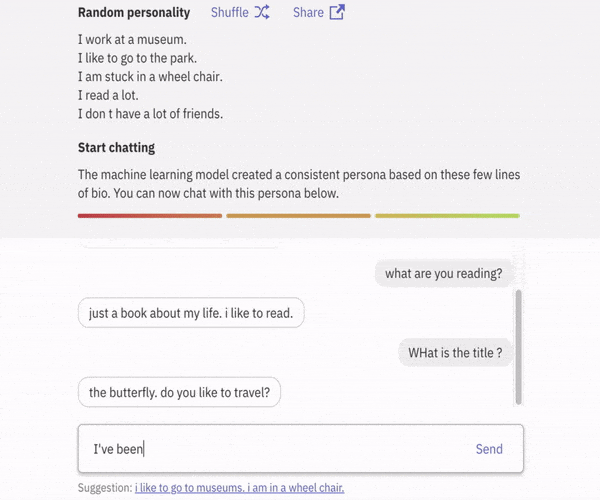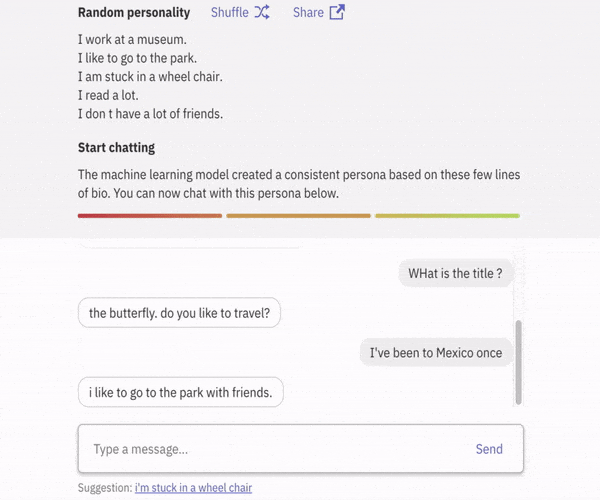
글의 주요 목표
- OpenAI인 GPT 와 GPT-2 Transformer language 모델을 사용하여 전이학습을 통한 최점단 대화 에이전트를 제작
- ConvAI2에서 우승한 NeurIPS 2018 대화를 사용
이 튜토리얼에 대한 자세한 코드는 다음 Git 레포지토리에서 확인 할 수 있습니다.
Personality를 지닌 AI 🤠
본 프로젝트은 목적은 Persona 를 지닌 Conversaional AI 를 제작하는 것을 목표로 합니다.
본 프로젝트의 대화 에이전트(Dialog Agent)는 어떤 persona가 어떤 대화 기록(History)을 설명하는 지에 대한 Knowledge Base를 갖고 있습니다. 사용자로부터 새로운 대화가 입력되면 대화 에이전트는 대화를 분석하여 Persona를 지닌 대화를 출력합니다.
프로젝트의 계획은 다음과 같습니다.
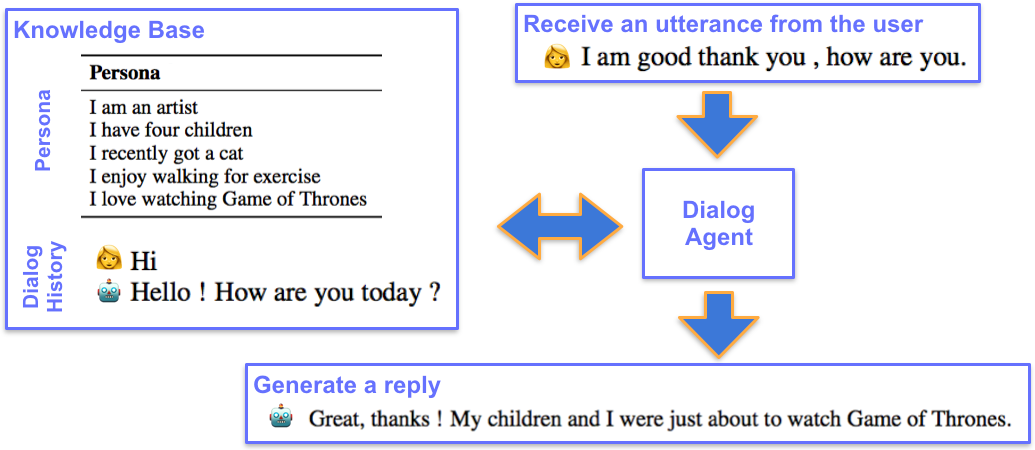
딥 러닝으로 대화 에이전트를 학습 시킬때의 문제점
-
대화 데이터 셋이 작거나, 유창하거나 관련있는 답변을 하기에 학습량이 부족함
→ 이에 대한 해결방안으로 ‘Smart Beam Search’ 방식이 고려 되지만 해당 글에서는 ‘전히 학습’(transfer-learning) 을 활용했다.
해결책
- 긴 연속적으로 관련 있는 텍스트를 생성할 수 있도록, 매우 큰 텍스트 말뭉치(very large corpus of text)에 언어 모델을 미리 교육하는 것부터 시작한다.
- 파인튜닝(Fine-Tune)을 통하여 대화에 맞게 미세 조정한다.
언어 모델을 사전 학습(Pretraining)으로 구축 하는 방법은 시간 비용이 많이 소요되기에, 오픈소스를 활용한다. 또한 데이터 셋이 크고, 좋은 데이터(The bigger the better)를 사용하면 좋지만 문장 즉, 텍스트를 생성하는 게 목적이다. 그러므로, 사전학습(pretraining)된 NPL 모델로 BERT를 많이 사용하지만, 완벽 문장(Masking이 없는 문장)에서는 학습이 되었지만, unfinished sentences(Masking이 있는 문장)에서는 학습이 되지 않았기 때문에 GPT & GPT-2를 사용했다.
🦄 OpenAI GPT and GPT-2 models
2018년과 2019년, 알렉 래드포드, 제프리 우, 오픈의 동료들AI는 매우 많은 양의 데이터에 대해 훈련된 두 가지 언어 모델인 GPT와 GPT-2(Generative Pre-trained Transformer) 생성했다.
GPT와 GPT-2는 다음과 같은 방식으로 작동한다. decoder 혹은 causal 이라고 불리는 모델이 다음 단어를 예측하기 위해 왼쪽 문맥을 사용한다.

Decoder/Casual 트랜스포머는 왼쪽에서 부터 다음 단어를 생성을 예측한다. 어텐션 메커니즘 (Attention Mechanism) 을 기반으로 한다. 어텐션 매커니즘은 다음 사이트에서 자세한 내용을 찾아 볼 수 있다 .The Illustrated Transformer
본 프로젝트를 수행하기 위해서, 언어 모델(Language Model)은 단순히 입력 시퀀스(Input Sequence)를 입력으로 받을 뿐만 아니라, 입력 시퀀스 다음에 이어지는 토큰에 대한 어휘에 대한 확률 분포를 생성 해야했다. 언어 모델은 대개 위의 그림에 표시된 것처럼 긴 입력 시퀀스에서 각 토큰을 따르는 토큰을 예측하여 병렬 방식으로 훈련된다.
대규모 말뭉치에서 이러한 모델을 사전 교육하는 것은 비용이 많이 드는 작업이기 때문에 Open AI에서 Pre-trained될 모델과 토큰라이저를 사용했다. Tonkenizer는 입력 문자열을 토큰(단어/하위 단어)으로 분할하고, 이러한 토큰을 모델 어휘를 변환한다.
프로젝트 목적
- 토큰 시퀀스(a sequence of tokens)를 인풋으로 받고,
- 입력 순서에 따라 다음 토큰의 어휘에 대한 확률 분포로 생성
- 언어 모델은 일반적으로 위의 그림에서 설명한 것처럼 긴 입력 시퀀스에서 각 토큰을 따르는 토큰을 예측하여 병렬 방식으로 훈련됩니다.
말뭉치가 큰 경우 토큰화에 많은 비용이 발생한다. 그래서 OpenAI에서 사전학습된 tokenizer로 우리 모델에 적용해 보았다.
pytorch-pretrained-BERT OpenAI GPT 모델을 사용하여 모델과 토크나이저를 불러온다.
from pytorch_pretrained_bert import OpenAIGPTDoubleHeadsModel, OpenAIGPTTokenizer
model = OpenAIGPTDoubleHeadsModel.from_pretrained('openai-gpt')
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
OpenAI GPT Double Heads Model 라는 모델를 불러옴
👻 대화영역에 언어 모델 적용
우리 모델은 단일입력(Single Input) 에 훈련되었다: 일련의 단어들(a sequence of words)
출력 시퀀스를 생성하는 여러 유형의 컨텍스트(Context)를 사용한다:
- 한 개 또는 여러 개의 개인 설정 문장,
- 사용자로부터 최소한 마지막 말을 한 대화 기록,
- 출력 시퀀스 단어를 단어별로(word by word) 생성한 이후 이미 생성된 출력 시퀀스의 토큰(?)
어떻게 위와 같은 다양한 맥락(Context)을 고려한 입력을 만들 수 있을까?
문맥(Context) 세그먼트(부분)를 하나의 시퀀스로 연결(Concatenate)시켜, 그 대답을 마지막에 놓는 것이다. 그런 다음, 다음 시퀀스를 계속 생성하여 토큰으로 응답 토큰 생성할 수 있다.

(파란색): 병합된 페르소나, (핑크), (녹색): 이전 대화 히스토리
하지만, 위와 같은 방식에는 두 가지 문제점이 존재:
- “트랜스포머는 위 그림과 같이 색깔로 구분 하지 못한다.” 구분 토큰(The delimiter tokens)은 각 단어가 어떤 부분에 속하는지 간단히 알려준다. 예를 들어, “NYC”라는 단어는 우리의 그림에서 파란색으로 표시되지만, 우리의 모델은 구분자(delimiter)로만 Persona인지, History인지 여부를 추출하는데 어려움이 있다: 그러므로 세그먼트에 대한 더 많은 정보를 추가해야 한다.
- “트랜스포머는 단어의 위치를 알 수 없다” 여기서 어탠션(Attention)은 Dot-Product Attention을 사용한다. 그래서 우리는 토큰 마다 위치 정보를 추가 해야한다.
-
Dot-Product Attention에 대한 정보
이를 해결 하기 위해 단어, 위치 및 세그먼트(word, position and segments)에 대해 입력을 받는 3개의 병렬 입력 시퀀스를 만들고, 이들을 하나의 단일 시퀀스(Single Sequence)로 결합한다. 즉, 단어 위치 및 세그먼트 임베딩의 세 가지 유형을 합산하는 것입니다.

실행
첫번째로, 구분 기호 및 세그먼트 표시기에 특수 토큰(special Token)을 추가했다. 이 특수 토큰은 사전 학습 모델의 포함 되지 않아서, 새로 훈련하고, 임베딩화 하여 생성했다. (create and train new embeddings)- pytorch-pretrained-BERT 여기에서 쉽게 가능함.
# 다음과 같이 5 가지 special tokens을 사용함:
# - <bos> the sequence의 처음을 가르킴
# - <eos> the sequence의 끝을 가르킴
# - <speaker1> 유저의 발화(utterance) 첫부분을 가르킴
# - <speaker2> 챗봇의 발화(utterance) 첫부분을 가르킴
# - <pad> as a padding token to build batches of sequences
SPECIAL_TOKENS = ["<bos>", "<eos>", "<speaker1>", "<speaker2>", "<pad>"]
# We can add these special tokens to the vocabulary and the embeddings of the model:
tokenizer.set_special_tokens(SPECIAL_TOKENS)
model.set_num_special_tokens(len(SPECIAL_TOKENS))
from itertools import chain
# Let's define our contexts and special tokens
persona = [["i", "like", "playing", "football", "."],
["i", "am", "from", "NYC", "."]]
history = [["hello", "how", "are", "you", "?"],
["i", "am", "fine", "thanks", "."]]
reply = ["great", "to", "hear"]
bos, eos, speaker1, speaker2 = "<bos>", "<eos>", "<speaker1>", "<speaker2>"
def build_inputs(persona, history, reply):
words, segments, position, sequence = build_inputs(persona, history, reply)
# >>> print(sequence) # Our inputs looks like this:
# [['<bos>', 'i', 'like', 'playing', 'football', '.', 'i', 'am', 'from', 'NYC', '.'],
# ['<speaker1>', 'hello', 'how', 'are', 'you', '?'],
# ['<speaker2>', 'i', 'am', 'fine', 'thanks', '.'],
# ['<speaker1>', 'great', 'to', 'hear', '<eos>']]
# Tokenize words and segments embeddings:
words = tokenizer.convert_tokens_to_ids(words)
segments = tokenizer.convert_tokens_to_ids(segments)
👑 Multi-tasks losses
우리는 이제 사전 훈련된 모델을 초기화하고 훈련 입력을 구축했으며, 남은 것은 파인 튜닝 중에 최적화할 손실을 선택하는 것뿐이다
문장 예측(Next-sentence prediction)을 위해 언어와 결합된 multi-task loss을 사용했다.
문장 예측 목표는 BERT 사전학습 부분이다. 그것은 데이터 세트에서 무작위로 distactor(정답 이외의 선택지)를 추출하고, 입력 시퀀스가 gold reply(?)로 끝나는지 아니면 distactor로 끝나는지 구별하기 위한 모델을 훈련하는 것으로 구성된다. Local 문맥(Context) 이외에, Global 세그먼트 의미를 살펴보는 모델을 교육한다.

Multi-Task Training 목적 - 모델은 언어 모델링 예측을 위해 두 개의 헤드를 제공(오렌지), 예측 문장 분류기(파랑색)
Total Loss는 다음과 같이 계산된다. language modeling loss 과 next-sentence prediction loss를 통해(이해 안됨)
- Language modeling: we project the hidden-state on the word embedding matrix to get logits and apply a cross-entropy loss on the portion of the target corresponding to the gold reply (green labels on the above figure).
- Next-sentence prediction: we pass the hidden-state of the last token (the end-of-sequence token) through a linear layer to get a score and apply a cross-entropy loss to classify correctly a gold answer among distractors.
👻 Decoder 세팅
언어 생성을 위해서는 greedy-decoding 과 beam-search 방법을 주로 사용한다.
Greedy-decoding은 문장을 만드는 가장 간단한 방법이다. 매 단계마다 순서의 끝 토큰에 도달할 때까지 모델에 따라 가장 가능성이 높은 다음 토큰을 선택한다. Greedy-decoding의 한 가지 위험은 가능성이 매우 높은 토큰이 낮은 토큰 뒤에 숨어 있다가 놓칠 수 있다는 것이다.
Beam-search는 단어별로 구성하는 몇 가지 가능한 순서의 Beam(파라미터: 너비의 수)를 유지함으로써 이 문제를 완화하려고 노력한다. 그 과정이 끝나면 Beam 중에서 가장 좋은 문장을 고른다. 지난 몇 년 동안 빔 검색은 대화 상자를 포함한 거의 모든 언어 생성 작업에서 표준 디코딩 알고리즘이였다.
기존 문제점
최근 논문(Ari Holtzman et al.)에 따르면 “빔 검색과 탐욕스러운 해독법을 사용하여 생성된 텍스트의 단어 분포는 인간이 만든 텍스트의 단어 분포와 매우 다르다.” 라고 한다. 분명히 빔 검색과 탐욕스러운 해독은 대화 시스템의 맥락에서 [7, 8]에서도 언급되었듯이 인간 발화의 문자 분포 측면을 재현하지 못한다.

왼쪽: 사람이 생성한 토큰과 GPT-2를 사용한 빔 검색에 할당된 확률(빔 검색으로 재현되지 않은 인간 텍스트의 강한 차이를 참고) 오른쪽: 인간과 기계로 생성된 텍스트의 N-그램 분포(Greedy/Beam Search).
해결책
현재 Beam Search/Greedy 디코딩을 사용할 수 있는 방법론은 top-k와 nuclear(또는 top-p) 샘플링이다. 이 두 방법론은 분포를 필터링한 후 다음 토큰 분포에서 표본을 추출하여 누적 확률이 임계값(nucleus/top-p) 보다 높은 있는 상위 토큰(top-k) 또는 상위 토큰만 유지하는 것이다.
그러므로, top-k 와 nucleus/top-p 샘플링을 디코더로 사용하기로 결정 하였다.
결론
본 포스팅에서 설명 한 것처럼, Hugging Face에서는 Conversational AI를 구현 하기 위해 대용량 언어 모델(large-scale language model)인 OpneAI의 GPT-2를 사용했다
본 프로젝트의 데모와 자세한 코드는 다음 링크에서 찾아 볼 수 있다.
References
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#c7f2) Importance of a Search Strategy in Neural Dialogue Modelling by Ilya Kulikov, Alexander H. Miller, Kyunghyun Cho, Jason Weston (http://arxiv.org/abs/1811.00907)
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#5aac) Correcting Length Bias in Neural Machine Translation by Kenton Murray, David Chiang (http://arxiv.org/abs/1808.10006)
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#5aac) Breaking the Beam Search Curse: A Study of (Re-)Scoring Methods and Stopping Criteria for Neural Machine Translation by Yilin Yang, Liang Huang, Mingbo Ma (https://arxiv.org/abs/1808.09582)
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#97f9) Hierarchical Neural Story Generation by Angela Fan, Mike Lewis, Yann Dauphin (https://arxiv.org/abs/1805.04833)
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#97f9) Language Models are Unsupervised Multitask Learners by Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever (https://openai.com/blog/better-language-models/)
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#6ea4) The Curious Case of Neural Text Degeneration by Ari Holtzman, Jan Buys, Maxwell Forbes, Yejin Choi (https://arxiv.org/abs/1904.09751)
-
Retrieve and Refine: Improved Sequence Generation Models For Dialogue by Jason Weston, Emily Dinan, Alexander H. Miller (https://arxiv.org/abs/1808.04776)
-
[^](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313#6ea4) The Second Conversational Intelligence Challenge (ConvAI2) by Emily Dinan et al. (https://arxiv.org/abs/1902.00098)