[논문리뷰] Hurdles to Progress in Long-form Question Answering
on
들어가며
오늘 포스팅은 ELI5 (Explain I am Five) 데이터셋에서 SOTA (State-of-the-art)를 기록한 LFQA 논문리뷰를 하겠습니다. 해당 논문은 ELI5 데이터셋 대회에서 SOTA를 기록 하였지만, 여러가지 문제점을 포함합니다. 해당 논문은 이러한 문제점에 대해 분석한 논문이며 포스팅 시작하겠습니다.
Abstract
- LFQA 란? : long-form question answering 의 약자로써, 질의(Question)에 유사한 Document를 Retrieval 한 뒤, 문단 길이의 답변(Answer)를 생성하는 태스크
- Spare Attention 기법과 constrastive retriever 학습 방법을 사용해 ELI5 데이터셋에 대해 SOTA를 기록
- 본 논문의 위 의 방법론이 갖는 지점에 대해 분석을 진행
- 본 논문의 시스템은 Retrieval를 통해 수집된 문서를 반영하여 답변 생성 X
- ELI5 데이터셋의 train과 valid는 최소 81%의 중복된(overlap) 데이터된 데이터 존재
- ROUGE-L 스코어는 LFQA의 생성 문장을 평가하기 위한 적절한 메트릭이 아님
- 다른 텍스트 생성 태스크에서 수행되는 휴먼 평가는 LFQA에 적합한 평가가 아님
Introduction
- LFQA는 Retriever 와 오픈 도메인 QA가 결합된 형태
- Retriever는 주어진 질의에 관련된 문서를 대용량 외부 저장소에서 찾아줌
- 본 논문의 Retriever는 REALM를 사용
- QA를 Retriever의 정보를 사용해 문단 길이의 답변을 생성
- 본 논문의 QA는 Sparse Attention이 가능한 Transfomer를 사용
- 데이터셋은 ELI5(Explain Like I’m Five)를 사용
- Retriever는 주어진 질의에 관련된 문서를 대용량 외부 저장소에서 찾아줌
- 이러한 방법론을 사용해 SOTA를 기록하였지만, 제안된 시스템은 Retriever가 수집한 문서를 사용하여 답변을 생성하지 않음!
- Retriever가 문장 생성 품질에 미치는 영향을 측정하기 위해, Retriever가 inference 진행시, 무작위로 샘플링된 문서를 사용해 문장 생성 실험을 진행
- 휴먼 평가와 Automated 메트릭를 통해, Retriever를 통해 관련 문서를 문장생성에 사용하는것 은 문장 생성 품질에 영향을 주지 않음을 밝힘(Fig 1c)
- 영향을 주지 않는 이유를 밝히기 위해 다음과 같은 분석을 진행
- ELI5 데이터셋의 train과 valid의 데이터 대부분은 overlap된 경우가 존재
- 휴먼 평가를 통해 최소 81%의 문장들이 paraphrased 되어 사용됨
- TF-IDF를 통해 중복된 질문을 제거 하는 방법론 등의 필요성을 제시
- 또한, 더 근본적으로 자동 메트릭인 ROUGE-L의 문제점을 제시
- 질문을 그대로 사용하여 훈련 데이터셋으로 사용해서 ROUGE-L를 측정하는 것은 LFQA의 시스템이 유리함
- 하지만, 실제 사람이 작성한 모법 답안 보다 LFQA 모델이 생성한 답변이 더 높은 ROUGE-L 스코어를 기록(이또한 휴먼 평가에서는 실제사람이 작성한 모범 답안의 점수가 더 높게 나와 오해의 소지는 있음)
- 번역이나 문서 요약과 같은 태스크에 비해 LFQA는 제약이 없는 출력 공간을 갖기 때문에 기존의 메트릭 방법론이 신뢰가능한 메트릭이 아님을 밝힘

LFQA 시스템
Retriever
- 본 논문의 Retriever는 REALM 혹은 c-REALM를 사용
- 질의와 답변을 represent하기 위개 다음 수식을 사용
- $\left(q_{i}, a_{i}\right)_{i=1}^{N}$
- Retriever는 위키피디아와 같은 대용량의 지식 베이스에서 $q_i$와 관련된 $K$개의 문서를 수집하는 것을 다음 수식으로 표현
- $\left(r_{i, j}\right)_{j=1}^{K}$
- 인코더 층은 질의와 관련 문서 후보를 128 차원에 임베딩을 진행
- REALM의 방법론과 같이 BERT 기반의 트랜스포머를 인코더로 사용
- ELI5는 gold Retrieval이 존재하지 않기 떄문에
- distant supervision를 위해 gold answer를 사용한 방법론을 사용해 기존의 Retriever를 확장해 학습을 진행
- 여기서 distant supervision이란, 미리 구축된 Freebase나 도메인에 특화된 데이터 베이스의 사실 정보에 기반해 트리플의 주어와 목적어가 포함된 문장을 수집해 학습 셋을 생성해 내는 방법.
- 학습의 핵심 아이디어는 contrasive learning!
- 인코딩된 벡터(질의, 답변)를 정답의 벡터 표현에 가깝게 근사하지만, 미니 배치에서 Negative sample은 멀리 근사되도록 학습하는것
- $B$는 미니 배치
- $\left(q_{i}, a_{i}\right)$ 는 질의와 답변이 인코딩된 벡터 표상
- $j$ 는 $i\neq j$ 인 negative sample
- 이러한 학습 방법은 dense retriever과 semi-supervised 학습에 사용된 방법론
- 기존의 BERT를 사용한 Retriever는 512개의 토큰수가 제한 되었지만,
- 본 논문은 크기를 키워 12,288의 토큰을 포함할 수 있는 REALM Retriever 모델을 사용
- REALM 모델은 Common Crawl News (CC-News) corpus로 학습됨
Generator
-
Retriever된 문서를 사용해, 긴 문장 생성이 가능한 QA모델인 Routing Transformer(RT) 를 사용
- RT는 sparse attention(local attention + routing attention(k-means))를 사용
- Sparse attention이란 local attension을 사용하고, k-means를 통해 미니배치를 사용해 길이가 긴 문장 생성에 적합한 모델
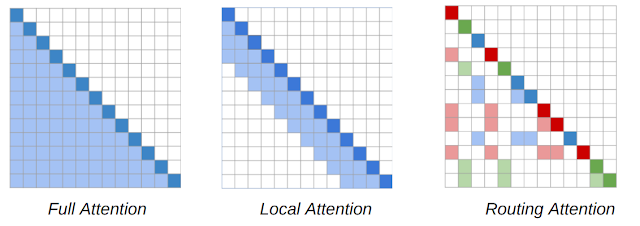
- RT는 ELI5 데이터셋에 적합한 모델임
- 짧은 질문에 다양한 문서를 포함해 답변을 생성 해야 하기 때문
-
데이터셋으로는 구텐베르크 도서관 프로젝트인 PG-19 데이터셋을 사용
- 이 데이터셋는 ELI5의 도메인 밖이지만, 길고 일관된 문장 생성을 위해 사용
-
RT는 1032개의 은닉 유닛(486M 매개변수), 8192 토큰의 최대 시퀀스 길이, 98K 하위 단어의 어휘가 있는 22계층 모델
-
미세조정은 fashion 분야의 데이터셋만을 사용
- Retrieval된 top-$K$의 문서를 질의와 답변을 concat 해서 사용
- $\left[r_{i, K}, r_{i, K-1} \ldots r_{i, 1}, q_{i}, a_{i}\right]$
Experiments
Dataset & Eval Settings
- Dataset: KILT Benchmark의 valid, test subset of ELLI5
- ELI5 dataset은 Retriever의 성능을 측정 할 수 있는 human annotation X
- 272,634 training examples, 1,507 validation examples, 600 test examples.
- Metric
- F1, ROUGE-L 스코어 사용
- Retriever 품질을 측정할 수 있는 ELI5 골드 답변을 사용하는 Wikipedia에 대한 휴먼 어노테이션을 진행
- R-precision: top-1 retrieval matches the annotation
- Recall@5: 상위 5 검색
- KILT ROUGE-L : R-prec과 ROUGE-L를 결합한 점수
Baseline
Generation task의 모델만을 비교 실험으로 사용
- T5-base (Raffel et al., 2020)
- BART (Lewis et al., 2020b),
- or variants of BART using retrieval such as RAG (Lewis et al., 2020c)
- BART + DPR
Result
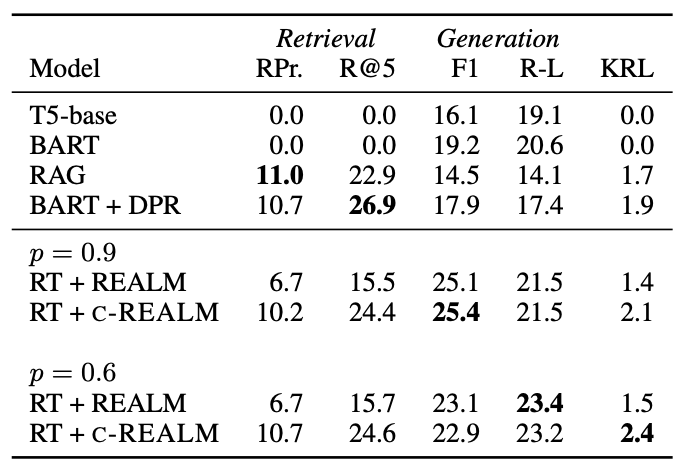
- nucleus sampling p values를 변경 하면서 모델 생성
- 엔트로피가 낮은 모델(p = 0.6)이 문장 생성 품질이 가장 좋음
- Retriever를 사용 함으로써 생성 품질을 높힐 수 있었음
Analysis
Are generators grounded in retrieval?
본 논문에서 제안한 모델이 SOTA를 기록 하였지만, Retriever의 결과를 매우 적게 반영된 점을 발견
이를 확인 하기 위해 위키 문서에서 랜덤으로 Retriever한 후에 생성 결과를 확인함
- Retriever된 문단과 생성 문장의 n-gram를 사용해 overlap 정도를 파악
Generations are similar irrespective of type of retrievals
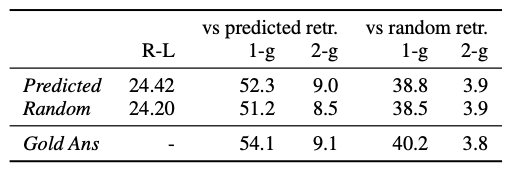
predicted: Retriever를 사용한 문서 예측, random: 무작위 샘플로 수집한 문서
-
ROUGE-L vs gold answers (R-L)의 차이가 없음
-
predicted retrievals vs predicted Retriever 간의 n-gram 차이 X
-
랜덤으로 문서를 수집했음에도 불구하고, 랜덤 검색 모델은 예측 시스템과 유사한 ROUGE-L 점수를 갖음
- 또한, C- REALM를 통해 수집한 문서를 통해 생성된 문장과 랜덤 문서를 통해 생성된 문장의 1-gram, 2-gram overlap이 거의 비슷
- Random 모델이 Retriever한 단락을 실제로 보지 않는다는 사실에도 불구하고, C-REALM에서 검색한 단락과 유사한 양의 1g 및 2g 겹침을 갖습
-
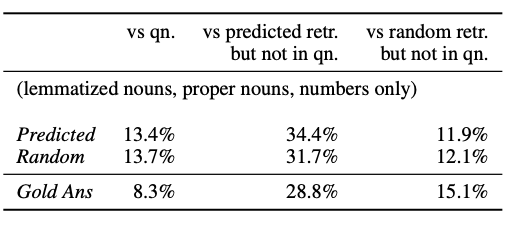
이러한 n-gram 방신은 마침표나 질의에서의 엔티티를 그대로 계산되는 경우가 있음으로, 숫자오 명사에 대해 lemmatized 후 추가 실험
- 그 결과 또한, 기존의 실험과 같이 Retriever에 따른 차이가 없음
- 예측 모델의 생성 품질과 출력과 검색된 문서(부록 A.7의 산점도) 사이의 유니그램 중첩 양 사이에는 거의 상관 관계(Spearman ρ = 0.09)가 없으므로
Human evaluation validates our findings:
-
Random 및 Predicted의 출력에 대해 추가 인적 A/B 테스트를 수행.
-
특히, 휴먼 어노테이터 에게 두 시스템에서 생성된 답변 중에서 선택하도록 요청

- 표 3에서 볼 수 있듯이 평가자는 두 가지 답변 중 어느 것이 질의과 더 관련이 있는지 선택함
- 두 모델 변형(p = 0.6, 0.9)의 경우 특정 답변 유형에 대한 선호도가 7% 미만이며, p = 0.9에 대한 무작위 모델의 답변(6%)을 선호하는 사람이 있습니다.
Other systems also have this issue, possibly due to source-reference divergence and train/validation overlap:
- 본 논문은 이 문제가 우리 시스템에만 있는 것이 아니라는 점에 주목
- BART + DPR 및 RAG와 같은 KILT 리더보드의 다른 시스템은 실제로 표 1에서 볼 수 있는 것처럼 문장 생성 품질에서 BART(no-retrieval counter)보다 성능이 더 나쁨
- 정성적으로, 우리는 Jernite(2020)의 공개 호스팅된 ELI5 모델 데모에서 Retriever 사용의 증거가 없음
- 이러한 문제의 이유는 table-text generation의 일반적인 문제인 high source-reference divergence일 수 있음 (Wiseman et al., 2017; Tian et al., 2019).
- 표 2와 표 4에서 예측된 검색과 함께 최상위 골드 검증 답변(Gold Ans)의 n-그램 중첩을 측정합니다.
- overlap은 낮고, 문장 생성의 overlap과 비슷하므로 우리 모델이 검색을 무시하는 것이 의심뙴
- 두 번째 설명은 검색이 필요하지 않은 많은 양의 트레인 유효성 검사 중복(섹션 3.2)입니다.
Why does our model do well compared to other systems despite not using retrievals?
- 우리 모델은 BART/RAG 기준선과 유사한 용량을 가지고 있지만(부록 A.3에서 비교), 우리는 ROUGE-L의 개선이 다른 사전 학습 목표로 인한 것이라고 가정
- BART는 짧은 시퀀스의 마스크 채우기 작업에 대해 사전 훈련됩니다.
- 대신, 길고 유창한 생성을 권장하는 Project Gutenberg의 긴 시퀀스에 대해 다음 단어 예측을 수행하도록 모델을 사전 훈련합니다.
- 이 길이 효과를 설명하기 위해 부록 A.6에서 논문의 모델이 truncated된 문장 출력이 ELI5에서 더 낮은 ROUGE-L 점수를 얻음을 보여줍니다.
- 더 짧은 길이의 출력에서 동일한 시스템을 비교하기 위해 우리는 또한 Wikipedia의 마법사(Dinan et al., 2019)에서 사전 훈련된 모델을 미세 조정하려고 시도했습니다.
- 공개 KILT 리더보드 에서 볼 수 있듯이 우리 시스템은 BART/RAG 기준선보다 ROUGE-L 점수가 낮습니다.
- 또 다른 가능한 설명은 섹션 3.3에서 논의된 바와 같이 ROUGE-L 자체의 문제입니다.
Takeaway (better evaluation of grounding):
- LFQA를 평가하려면 무작위 Retriever으로 제어 실험을 실행하고 Retriever에서 문장 생성를 측정하는 것이 중요
- KILT 벤치마크는 KILT-RL을 통해 결합된 Retriever+ 문장 생성 성능을 측정하려고 시도하지만, 문장 생성이 실제로 Retriever을 사용했는지 여부는 확인 X
- 즉, 독립적인 Retriever및 generation을 제출할 수 있지만, 통합 점수에서는 여전히 좋은 성능을 보임
- Gold answer는 종종 gold Retriever의 범위로 정확히 포함되기 때문에 natural 질의와 같은 짧은 형식의 QA 작업에서는 문제가 되지 않을 수 있음
- 또한, Retriever이 매개변수 지식이 있는 대규모 언어 모델의 경우 덜 중요할 수 있으므로(Roberts et al., 2020), 단순히 top-1 Retriever 점수를 ROUGE-L로 집계하는 KILT-RL 전략은 검색에 의존하지 않는 시스템에 부당하게 불이익을 줌.
Training / Validation Overlap
-
섹션 3.1의 우리의 실험은 C-REALM의 예측 대신 무작위로 샘플링된 Retriever에서 Generation을 조건화함으로써 모델 성능이 변함이 없음
-
Retriever를 사용하지 않음에도 불구하고, 우리는 정성적으로 a large amount of parametric knowledge(“Faraday Cage”) 을 보여줌
- 이는 PG19(위키피디아가 아님)의 소설에서 사전 훈련되었기 때문에 놀랍다.

-
이 섹션에서, 우리는 Retriever을 무시하는 주요 이유가 ELI5에서 대량의 train/vaild 검사 중복 때문이라는 것을 발견
-
While Fan et al. (2019) attempted to fix this issue through TF-IDF overlap
- 이러한 방법론으로 모든 질문이 paraphrases되어 있는지는 확인 불가능
- 우리는 train 데이터와 KILT validation set of ELI5의 대용량의 overlap을 확인
- Lewis et al. (2020d) identify similar issues with short-form QA datasets like Natural Questions.
Finding similar questions & measuring overlap:
- 질문을 기능이 feature-rich embedding space에 매핑하는 방법을 학습했기 때문에, C-REALM을 사용하여 train set에서 유사한 질문을 Retrieve를 함.
- Retriever는 매 validation 질문 마다, training set에서 유사 질문 7개를 수집함
-
automatic evaluation과 human eval을 overlap을 계산하기 위해 사용
-
Human Evaluation
- Turker들에게 validation set question과 retrieved training set question을 검사 하도록 요청
- 0: No paraphrase relationship
- 1: on similar topics but different questions
- 2: approximately the same question
- Datataset: 300 validation set questions, three crowd-workers

-
valid 데이터셋의 81%가 training set에서 최소한 한 번이라도 paraphrase 되었음을 확인
-
annotated 된 모든 질문은 훈련 세트에 적어도 하나의 주제적으로 유사한 질문을 가지고 있으며,
–> 이는 상당한 train/valid 중복을 나타냄
- Turker들에게 validation set question과 retrieved training set question을 검사 하도록 요청
-
Automated Evalution
-
Model : RoBERTa-large binary classifier (Liu et al., 2019)
-
Dataset(find-tuned): fine-tuned on the Quora Question Paraphrase (QQP) datase
-
ELI5 Valid 데이터셋의 43.6%가 적어도 하나의 Retriever된 질문을 paraphrased 되었었다고 나타냄
- (46% for the 300 questions we annotated)
-
Using retrieved QA for generation
-
ELI5 contains significant amount of overlap between the training and validation set
-
a system can simply copy the answers of retrieved training set questions instead of actually doing generation

using the longest answer within the top-K retrieved questions
- retrieval-augmented generation을 사용해서 RAG, (BART + DPR) 보다는 더 좋은 성능을 보임
- uses the best possible answer to retrieved training set questions in terms of ROUGE-L (best top-K train answer)
ELI5 performance on overlapping QA
- Overlap(Train/Valid) vs no Overlap
- no- overlap subset has only 53 samples (300개 중)

We see the overlap subset has much better retrieval performance and slightly better generation performance.
6.6 RPrec, 8.1 R@5 in retrieval performance favoring the overlap subset, but only a small generation score gain of 0.8 F1, 0.4 R-L
Takeaway
-
중복을 방지하기 위해 LFQA 작업에 대한 보다 신중한 데이터 세트 큐레이션이 필요하다고 제안
- 중복을 제어하고, held-out sets에서 generalization 평가에 초점을 맞추는 대체 방법을 제안
- (1) 자동으로 Retriever 문단을 수집하고, 휴먼 검증을 통해 overlap을 제거 한다.
- (2) overlap 가능성을 줄이기 위해 전체 장르 또는 domin을 유지함.
- 예를 들어, 스포츠에 대한 Q/A를 held-out 세트에서만 유지
- 이러한 기준으로 데이터를 split 하면 held-out dataset의 크기가 현저히 줄어든다.
- 우리는 전체 데이터셋을 다시 합쳐서 처음부터 train/valid/test 을 나누는 것을 주장
ROUGE-L Bounds on ELI5 Performance
훈련 세트에서 가까운 질문의 답을 복사하는 것만으로도 검색된 질문 중에서 최적의 선택으로 28.5 ROUGE-L을 달성하고 모든 계산 모델을 능가하는 것을 보았습니다.
그러나 이 절대 수치가 얼마나 “좋은” 것입니까? ELI5의 ROUGE-L 점수에 대한 적절한 상한 및 하한은 무엇입니까? ROUGE-L은 LFQA에 대한 유익한 지표입니까?
Lower Bound
- Lower Bound는 데이터셋 혹은 metric의 취약성을 검증하기 위한 휴리스틱한 방법이다. 이 방법은 실제 특정한 작업을 하지 않고 수행됨
- ELI5에서 두 개의 ROUGE-L 하한을 평가를 위해 두 가지 기준을 사용
- hypothesis-only baselines for natural language inference (Gururangan et al., 2018)
- passage-only baselines for reading comprehension (Kaushik and Lipton, 2018)
- 더 긴 출력이 더 높은 ROUGE-L 점수을 기록 하기 때문에 질문을 5번 복사하고 연결합니다(부록 A.6).
- 무작위로 training set의 answer를 Retriever함
(1)의 baseline은 Gold answer에 자주 나타나지만, 실제로 질문에 답변하지 않은 엔터티가 포함됨
(2)는 답변의 “스타일”이지만 완전히 주제에서 벗어남
Upper Bound
- Upper Bound으로 gold answer자체의 ROUGE-L을 추정
평균적으로 질문당 12개의 gold answer이 있으므로, 다른 골드 답변에 대해 가장 긴 골드 답변의 ROUGE-L을 측정합니다.
또한 동일한 질문에 대한 두 개의 골드 답변 간의 최대 쌍별(overlap) ROUGE-L을 측정합니다.
KILT test 세트의 gold answer가이 숨겨져 있기 때문에 valid 세트의 상한만 계산합니다.
Lower bounds beat prior work, upper bounds have low ROUGE-L

- 하한은 이전 작업을 능가하고 상한은 ROUGE-L이 낮습니다.
- 우리의 Lower Bound(무작위 훈련 답변, 복사 입력)은 모두 경쟁력이 있으며 RAG보다 성능이 뛰어남
- 실제로 질문에 대답하지 않고 BART + DPR(Petroni et al., 2020)에 가깝게 수행합니다!
- 이것은 ROUGE-L이 ELI5의 stylistic properties(문체 특성)뿐만 아니라 질문의 엔터티를 단순히 복사하는 데 상당히 민감하다는 것을 보여줍니다.
- 반면에 상한값(가장 긴 금색 답변)은 우리 시스템(21.2 대 24.4)보다 성능이 좋지 않습니다.
- 이 결과가 오해의 소지가 있다고 의심되는 우리는 지원자에게 질문을 보여주고 우리 시스템에서 생성된 답변과 무작위로 섞인 가장 긴 금색 답변 중에서 선택하도록 요청하여 또 다른 인간 A/B 테스트를 실행합니다.
- 표 3에서 볼 수 있듯이 대다수는 의 인간이 세대에 비해 금 참조 답변을 선호합니다(p = 0.6의 경우 68% 대 14%).
- 작업을 완료한 후 인간 어노테이터와의 인터뷰에서 그들은 두 답변이 종종 유창하고 스타일적으로 유사했지만 하나는 결국 주제에서 벗어났다고 보고했습니다.
Takeaway
better automatic metrics needed!
골드 응답에 대해 Generation의 ROUGE-L을 계산하는 것이 valid/invalid 응답을 구별하기에 충분히 선택적이지, 않기 때문에 LFQA 시스템을 평가하는 의미 있는 방법이 아님을 주장
- trivial lower bounds와 strong upper bounds 사이에 small margin of improvement만이 존재.
- 심지어 upper bounds 의 절대적 점수는 매우 낮음
- 이것이 답변의 긴 길이와 상당히 제약이 없고 큰 출력 공간 때문이라고 생각합니다.
-
ELI5 데이터 세트에는 많은 그럴듯한 답변(예: 트래픽의 원인은 무엇입니까?)이 포함된 몇 가지 개방형 질문(open-ended questions)이 있으며 종종 유추를 포함함.
- 가능한 수정은 문장 수준 평가와 Generation된 문장 전체의 점수를 집계하는 것이지만, 다양성 부족(Zhu et al., 2018) 및 짧은 길이에 대한 적절한 penalties이 필요하다.
- 다른 가능한 수정에는 의미론적 중복(semantic overlap )을 측정하기 위한 학습 작업별 메트릭(Sellam et al., 2020) 또는 사실적 정확성(check factual correctness)(Zhang et al., 2020) 및 입력에 대한 충실도(faithfulness to input)를 확인하기 위한 메트릭(Wang et al., 2020; Durmus et al.)이 포함됩니다. ., 2020; Zhou et al., 2020).
- 또한, 궁극적으로 모든 자동 메트릭에는 한계가 있으며 사람의 평가가 필요합니다(Celikyilmaz et al., 2020).
Difficulty of Human Evaluation
ELI5에서 평가의 고유한 어려움을 더 잘 이해하기 위해 인간 주석가(표 3)를 인터뷰하고 두 가지 문제를 발견했습니다.
(1) Unfamiliarity with question topics
-
질문 주제에 익숙하지 않음: 대부분의 주석가는 Q/A를 흥미롭게 보았지만 질문에서 논의된 기술 주제에 익숙하지 않은 경우가 많았습니다.
-
이것은 그들이 답의 정확성을 평가하기 어렵게 만들었습니다.
- ELI5 데이터 세트에는 다양한 주제(역사, 정치, 생물학 등)에 대한 질문이 있으며 대부분의 주석은 컴퓨터 과학 대학원생이었습니다.
- 우리는 주석가가 Wikipedia를 사용하도록 허용했지만 도메인 전문가가 답변의 사실적 정확성을 더 잘 판단할 것이라고 언급했습니다.
-
(2) Length of Answers:
- 주석가는 단락 길이의 답변이 작업을 상당히 어렵게 만들었다고 언급했습니다.
- 주석가는 답변 쌍당 평균 2분이 소요된다고 보고했으며, 그 중 많은 부분은 신중한 생각과 집중이 필요했습니다.
- 답의 일부만 맞고 나머지는 모순이나 반복이 있을 때 특히 어려웠습니다.
Conclusion
- 본 논문은 “retrieval augmented” generation system 을 제안함
- 이것은 ELI5 long-form question answering datase에서 SOTA를 기록
- 하지만, 우리의 모델과 ELI5의 데이터셋과 평가 방법에서 여러 이슈가 존재
- 우리는 이것이 해결되길 원한다.
Ethical Considerations
우리 시스템은 사실 조작(Zellers et al., 2019), 오용 가능성(Brown et al., 2020) 및 Reddit에 만연한 편견 반영(ELI5)과 같은 대부분의 현대 텍스트 생성 기술과 유사한 일련의 문제에 직면해 있습니다. 데이터 세트는 r/ELI5 하위 레딧을 사용하여 구축되었습니다. 우리의 작업에서 우리는 사실 조작을 줄이기 위해 검색된 Wikipedia 기사에 세대를 조건화하여 텍스트 생성기를 보다 사실적으로 만들려고 시도했습니다. 불행히도, 철저한 분석(섹션 3.1)에 따르면 우리 시스템은 여전히 검색에서 해당 세대를 기반으로 하지 않으며 이 문제를 해결하기 위해 사실적 정확성을 측정하기 위해 더 나은 메트릭을 설계할 것을 권장했습니다.