[PRML] 1장 - 확률론
on
들어가며
패턴 인식 분야에 있어 불확실성(uncertainty)는 가장 중요한 개념 중 하나 입니다. 불확실성은 데이터를 측정할 때의 노이즈를 통해서도 발생하고, 데이터의 수가 적어서 발생하기도 합니다. 이때 확률론은 이러한 불확실성을 계량화 하고 조직화하기위 한 이론적인 토대를 마련 해줍니다.
확률론(Probability Theory)
불확실성을 정확하고 정량적으로 표현할 수 있는 이론적 정보를 제공
결정이론(Decision Theory)
불완전하고 모호한 정보로 부터 최적의 예측을 마련할 수 있도록 도와줌
확률 변수
확률 변수 $X$는 표본의 집합 $S$의 원소 $e$를 실수값 $X(e) = x$에 대응시키는 함수 이다.
- 대문자 $X, Y, \ldots$ : 확률변수
- 소문자 $x, y, \dots$ : 확률변수가 가질 수 있는 값
- 확률 P는 집합 S의 부분집합을 실수값에 대응 시키는 함수
예제
예를 들어 주사위 두개를 던진다고 가정해보자. 그렇다면 표본공간 $S$ 는 다음과 같이 구성될 것이다.
\[S = \{H H, H T, T H, T T\} \\ \text{H: head T: tail}\]이 때, 확률변수 $X$를 H(head)가 나온 횟수로 정의 할 수 있다. 이때 각 확률 변수의 값은 다음과 같이 정리 된다.
\[X(H H)=2, \quad X(H T)=1, \quad X(T H)=1, \quad X(T T)=0\]이렇게 확률변수는 일종의 하나의 함수의 역할 즉, 어떠한 조건의 실수를 매핑 해주는 역활을 한다. 이 때 임의의 확률을 계산 한다고 가정해보자. $P[X=1]$ 의 확률은 어떻게 될까? 또는 확률변수가 1보다 작은 경우 H가 1개 이하만 나올 확률을 구하면 다음과 같다.
\[P[x=1]=P[\{H T, T H\}]=\frac{2}{4}=\frac{1}{2}\\ P[x \leqslant 1]=P\{H T, T H, T N\}=\frac{3}{4}\]연속확률변수(Continous Random Variable)
누적분포함수(Cumulative Distribution Function)
누적 분포 함수란 확률변수 $X$가 임의의 범위 안에 있을 확률을 나타낼 때 사용한다. 주로 대문자 $F$ 를사용해서 이를 표현한다.
\[F(x)=P[X \in(-\infty, x)]\]확률밀도함수(Probability Density Function)
누적분포함수 $F(X)$를 가진 확률변수 $X$에 대해서 다음을 만족하는 함수 $f(x)$가 존재한다면 $X$를 연속확률변수라고 부르고 $f(x)$를 $X$의 확률밀도함수(probabilty density funciton, pdf)라고 부른다. \(F(x)=\int_{-\infty}^{x} f(t) \mathrm{d} t\)
- 확률변수를 명확하기 위해 $F_{X}(x), f_{X}(x)$로 쓰기도 한다. (확률변수: $X, Y$등 사용가능)
- 혼란이 없을 경우 $f_{X}(x)$ 대신 $p_{X}(x), p_{x}(x), p(x)$를 사용하기도 한다.
- $p(x) \geq 0, \int_{-\infty}^{\infty} p(x)=1$
확률변수의 성질(The Rules of Probabilty)
여기서 표현되는 $p$는 전부 확률밀도함수를 가르킨다.
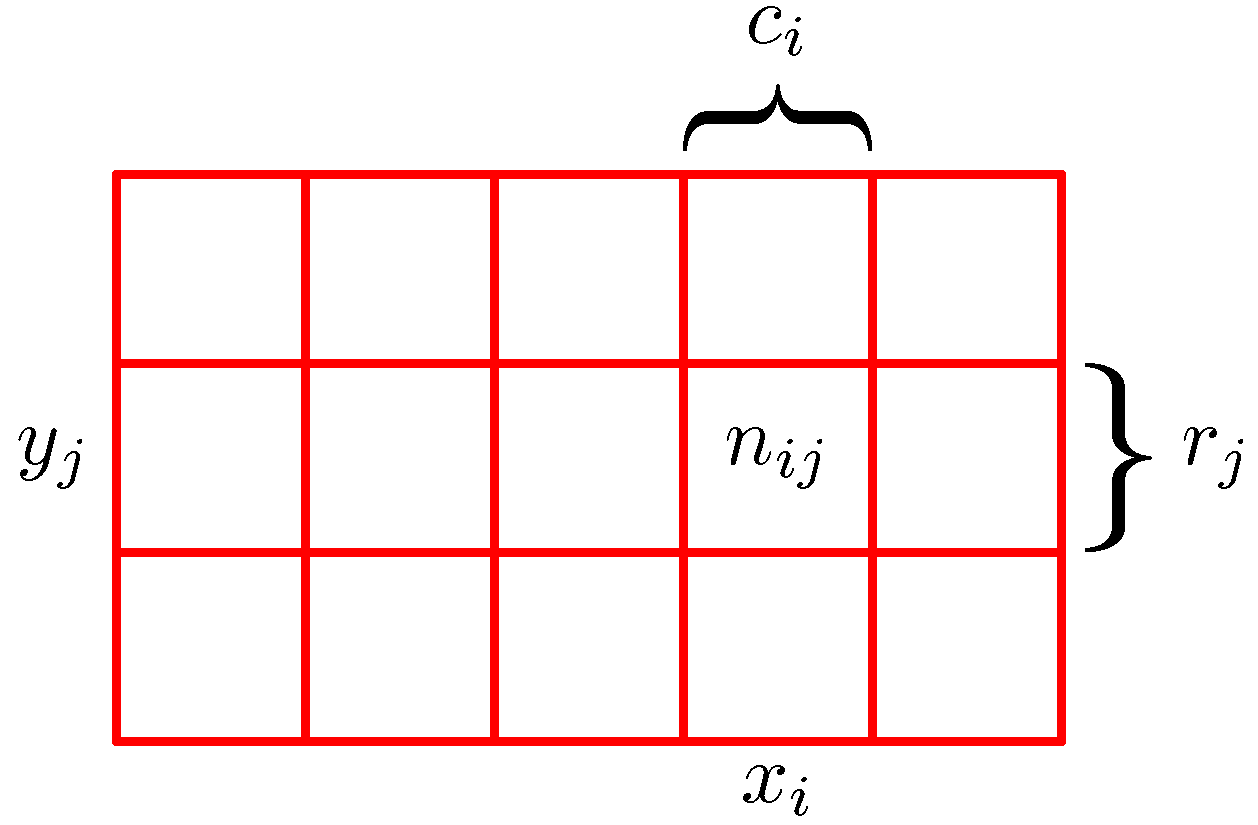
덧셈법칙 (sum rule)
\[p(X)=\sum_{Y} p(X, Y)\]다음 수식에서 확률변수가 $X, Y$ 두 개 존재하는 것을 유심히 살펴보자. 다음과 같이 $X, Y$가 결합 되었을때 결합확률(Joint Probabilty)라고 한다.
주변확률(Marginal Probability)
\[p\left(X=x_{i}\right)=\frac{c_{i}}{N}\]이렇게 두가지가 주어졌는데 $X$에 대해 확률을 구하고, $Y$에 대해 확률을 따로 따로 구해 그 값을 더한 것을 주변화(Marginalize)라고 한다.
조건부 확률(Conditional Probability)
\[p\left(Y=y_{j} \mid X=x_{i}\right)=\frac{n_{i j}}{c_{i}}\]여기서는 $X=x_i$인 사례들만 고려해 보자. 그들 중에서 $Y = y_i$인 사례들의 비율을 생각해 볼 수 있고, 이를 확률 $p(Y=Y_i \mid X= x_i)$로 적을 수 있다. 이를 조건부 확률 이라고 한다.
곱셈법칙
조건부 확률을 변형하여 다음과 같이 곱셈법칙을 사용할 수 있다.
\[p(X, Y)=p(X \mid Y) p(Y)=p(Y \mid X) p(X)\]베이즈 확률
일반적으로 $X$가 주어지고 $Y$를 구하는 형태가 아니라 $Y$를 통해 $X$를 구하는 형태가 더 쉬울 경우 사용하는 방법론이다. 즉, 사후확율을 구하기 위해서 사전확률을 이용하는 방법이다.
\[\begin{aligned} p(Y \mid X) &=\frac{p(X \mid Y) p(Y)}{\sum_{Y} p(X \mid Y) p(Y)} \\ \text { posterior } &=\frac{\text { likelihood } \times \text { prior }}{\text { normalization }} \end{aligned}\]- posterior: 사후확률
- likehood: 우도
- prior: 사전 확률
- normaliztion: $Y$와 상관없는 상수, $X$의 경계확률(marginal) $p(X)$
예제
어떤 한 종류의 과일을 선택했는데 그것이 오렌지이고, 이 오렌지가 어떤 상자에서 나왔는지를 알고 싶다고 가정해보자. 이를 위해서는 과일이 주어졌을 때 고른 상자가 어떤 것인지에 대한 조건부 확률을 계산 해야 한다.
- 확률 변수 $B$: 박스를 선택할 확률
- 확률 변수 $F$: 과일을 선택할 확률
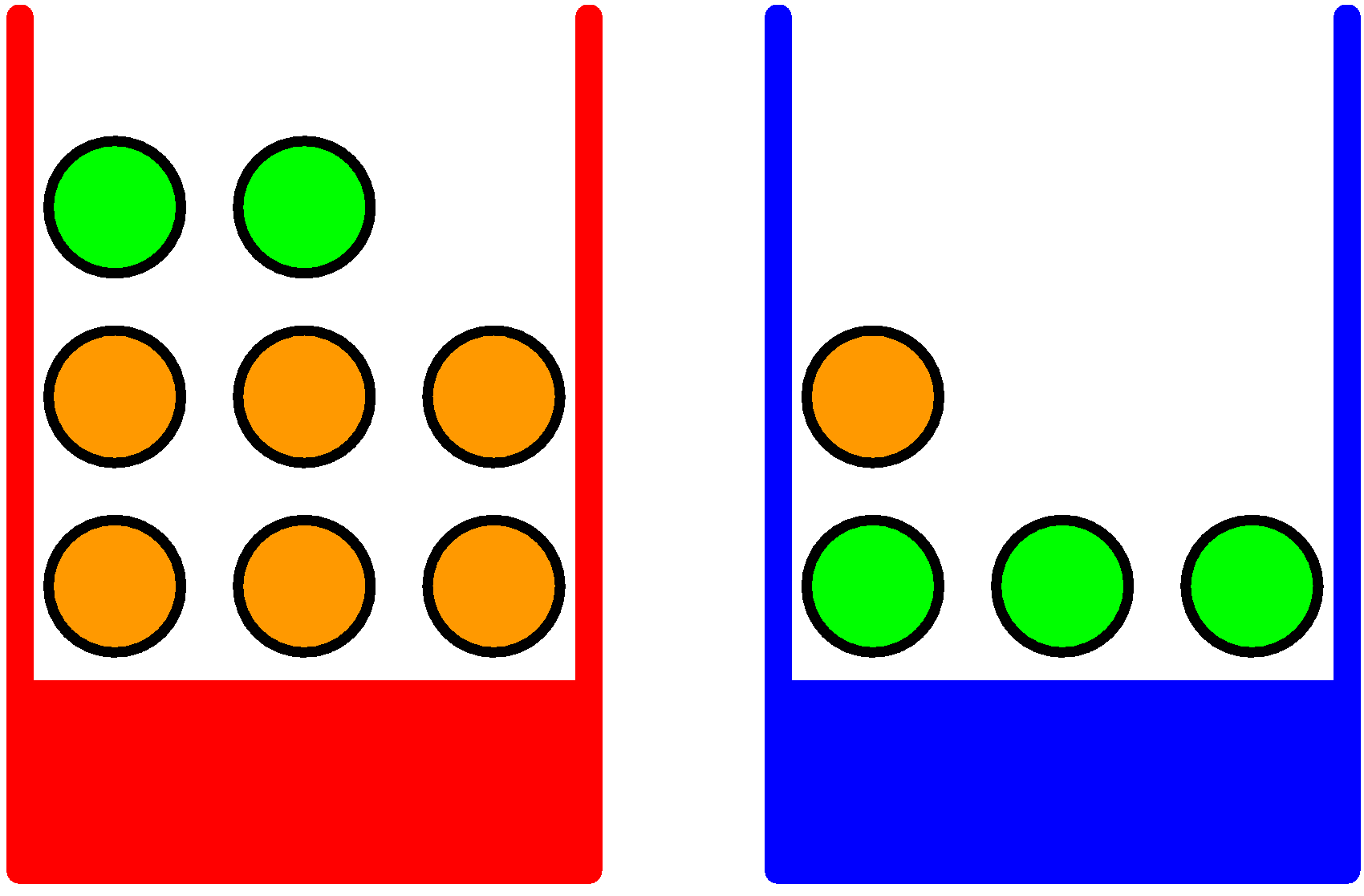
베이지안 해석
베이지안 정리를 다음과 같이 해석 할 수 있다. 만약 어떤 과일이 선택되었는지를 알기 전에 어떤 박스를 선택했내고 묻는다면 그 확률은 $P(B)$일 것이다. 이를 사전확률(prior probability)라고 부른다. 왜냐하면 어떤 과일이 선택되었는지 관찰하기 ‘전‘의 확률 이기 때문이다.
선택된 과일이 오렌지라는 것을 알게 된다면 베이지안 정리를 확용하여 $p(B \mid F)$를 구할 수 있다. 이를 사후확률이라고 부를 수 있다. 그 이유는 사건 $F$를 관측 ‘후‘의 확률이라 그렇다.
예제
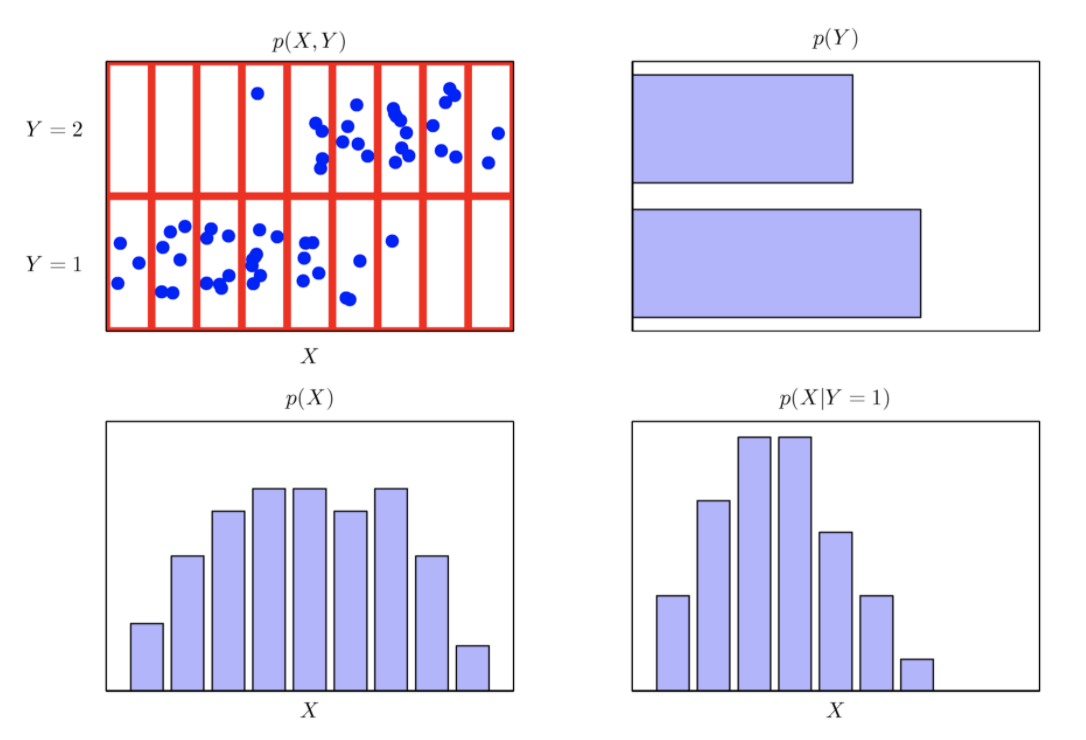
주변확률(Marginal)분포, 조건부(conditional) 확률분포
다음 그림과 같이 데이터가 분포되어 있을때 주변확률 분포인 $p(Y)$ 와 $p(X)$를 구할 수 있고 또한 조건부 확률 분포도 다음과 같이 구할 수 있다.
확률변수의 함수(Functions of Random Variable)
확률변수 $X$의 함수 $Y=f(X)$도 확률변수이다. (즉, 함수의 함수) 예를 들어, 확률변수 $X$가 주(week)의 수로 표현되었다고 할 때, 일(Day)의 수로 표현된 새로운 확률변수를 정의할 수 있다.
\[\begin{array}{c} Y=7 X \\ P[14 \leq Y \leq 21]=P[2 \leq X \leq 3] \end{array}\]확률변수 $X$의 함수 $Y=g(X)$와 역함수 $w(Y)=X$가 주어졌을 때 다음이 성립한다. 즉 확률변수 $X$에 대한 확률밀도함수를 $y$에 대해 미분을 하게되면 $y$에 대한 확률밀도함수를 구할 수 있게 된다.
\[p_{y}(y)=p_{x}(x)\left|\frac{\mathrm{d} x}{\mathrm{~d} y}\right|\]일반화
$\begin{array}{l}
k \text { 차원의 확률변수 벡터 } \mathbf{x}=\left(x_{1}, \ldots, x_{k}\right) \text { 가 주어졌을 때, } k \text { 개의 } \mathbf{x} \text { 에 관한 함수들 } y_{i}=g_{i}(\mathbf{x}) \text { for }
i=1, \ldots, k \text { 는 새로운 확률변수벡터 } \mathbf{y}=\left(y_{1}, \ldots, y_{k}\right) \text { 를 정의한다. 간략하게 } \mathbf{y}=\mathbf{g}(\mathbf{x}) \text { 로 나타낼 수 있다. }
\end{array}$
예를 들어, 확률 변수가 $x_1, x_2,\dots, x_k$ 와 $y_1, y_2, \dots, y_k$ 로 주어졌다고 가정해 보자. 이때, $y_1 = g_1(\bold{x})$ 의 관계 성립한다고 가정한다. (여기서 볼드체 $\bold{x}$ 는 $x$ 벡터들의 집합을 나타냄) 즉, $y_1 = g_1(x_1, x_2, \dots, x_k)$ 을 나타낸다. 이러한 $y$의 확률 집합들의 확률밀도함수가 궁금한 것이다.
이것을 구하기 위해서는 $x$의 확률밀도함수 즉, $p_x(x_1,x_2, \dots, x_k)$ 에 $\mathbf{J}$를 곱해 $y$의 결합확률밀도함수를 구할 수 있게 된다.
만약 $\mathbf{y}=\mathbf{g}(\mathbf{x})$ 가 일대일(one-to-one)변환인 경우 $(\mathbf{x}=\mathbf{w}(\mathbf{y})$ 로 유일한 해를 가질 때), $\mathbf{y}$ 의 결합확률밀도함수 (joint pdf)는 다음과 같이 나타낼 수 있다.
\(\begin{array}{l}
p_{\mathbf{y}}\left(y_{1}, \ldots, y_{k}\right)=p_{\mathbf{x}}\left(x_{1}, \ldots, x_{k}\right)|\mathbf{J}| \\
\mathbf{J}=\left|\begin{array}{ccc}
\frac{\partial x_{1}}{\partial y_{1}} & \frac{\partial x_{1}}{\partial y_{2}} & \cdots & \frac{\partial x_{1}}{\partial y_{k}} \\
\frac{\partial x_{2}}{\partial y_{1}} & \cdots & \vdots \\
\vdots & & \\
\frac{\partial x_{k}}{\partial y_{1}} & \cdots & \frac{\partial x_{k}}{\partial y_{k}}
\end{array}\right|
\end{array}\)
예제
$p_{x_{1}, x_{2}}\left(x_{1}, x_{2}\right)=e^{-\left(x_{1}+x_{2}\right)}, x_{1}>0, x_{2}>0$ 이라고 하자. $y_{1}=x_{1}, y_{2}=x_{1}+x_{2}$ 에 의해서 정의되는 $y$의 pdf는? \(J=\left|\begin{array}{cc} \frac{\partial x_{1}}{\partial y_{i}} & \frac{\partial x_{1}}{\partial y_{2}} \\ \frac{\partial x_{2}}{\partial y_{1}} & \frac{\partial x_{2}}{\partial y_{2}} \end{array}\right|=\left|\begin{array}{cc} 1 & 0 \\ -1 & 1 \end{array}\right|=1\)
Inverse CDF Technique
확률변수 $X$가 CDF $F_X(X)$를 가진다고 하자. 연속확률분포함수 $U \sim \operatorname{UNIF}(0,1)$ 의 함수로 정의도는 다음 확률변수 $Y$를 생각해보자.
\(Y=F_{X}^{-1}(U)\) 확률변수 $Y$는 확률변수 $X$와 동일한 분포를 따르게 된다.
\[\begin{aligned} F_{Y}(y) &=P[Y \leq y] \\ &=P\left[F_{X}^{-1}(U) \leq y\right] \\ &=P\left[U \leq F_{X}(y)\right] \\ &=F_{X}(y) \end{aligned}\]베이지안 확률
베이즈 정리를 간단히 설명하면 어떤 사건이 서로 배반하는 원인 둘에 의해 일어 난다고 할 때, 실제 사건이 일어났을 대 이것이 두 원인 중 하나일 확률을 구하는 정리를 베이즈 정리하고 합니다.
결국 조건부 확률(사후 확률)을 구하는 것을 말하는데, 이는 어떤 사건을 만들어 놓은 상황에서, 그 사건이 일어난 후 앞으로 일어나게 될 다른 사건의 가능성을 구하는 것을 말합니다. 즉, 기존 사건들의 확률(사전 확률)을 알고 있다면, 어떤 사건 이후의 각 원인들의 조건부 확률을 알 수 있다는 말 입니다. 최근 빅데이터를 통해 기존 사건들을 대략적으로 확률을 뽑아 낼 수 있게 되면서(새로운 관측) 베이즈 정리의 활용이 필수적인 것으로 되고 있습니다.
빈도론자(Frequentist)
확률을 고려하는데 임의적으로 발생하는 사건의 바탕으로 식을 전개하는 방식을 사용합니다. 빈도론적인 입장에서는 실제 데이터가 존재해야 불확실성을 정량화 할수 있습니다.(빈도를 통해 모델링 하기 때문에)
베이지언(Bayesian)
베이지언 관점에서는 모든 것이 불확실합니다.(불확실성을 정량화하는 것을 목표 ). 베이지언은 확률을 빈도의 개념이 아니라 믿음의 정도로 해석하는 관점을 말합니다. 따라서, 베이지안 방식이 좀 더 불확실한 경우에도 모델링이 가능합니다.
베이지안 예제
예를 들어 ‘‘북극 얼음이 이번 세기에 녹아 없어질 확률’ (실제로는 아직까지 일어난 사건이 아님)을 서술할 수 있습니다. 즉, 사전 확률 모델을 작성하고 새로 계측된 데이터를 통해 사후확률을 보정하는 방식으로 확률을 계산 할 수 있는 것 입니다. (새 증거가 주어질 때마다 불확실성을 수정할 수 있고 최적의 선택을 내릴 수 있게 됩니다.)
패턴인식에 적용
앞에서 설명한 다항식 곡선 피팅 예시를 다시 한 번 생각해 봅시다. 관찰값 $t_{n}$에 대해서는 확률의 빈도적 관점을 적용하는 것이 적합해 보일 수 있습니다. 하지만, 모델 매개변수 $\mathbf{w}$를 정하는데 있어서의 불확실성을 수치화 하고 표현하려면 어떻게 해야 할까요? 이때 베이지안을 사용하면 이러한 불확실성을 정량화 하여 표현이 가능해집니다.
베이즈 정리를 통해서 사전확률의 불확실성을 관측된 데이터의 분포(=가능도)를 통해서 갱신이 가능했습니다.
다음 식을 통해, 다항식 곡선 피팅 문제에도 가중치에 대한 불확실성을 표현 할 수 있습니다. 다음 식의 의미는 $D$ 를 관측한 후의 $\mathbf{w}$(가중치)에 대한 불확실성을 사후확률 $p(\mathbf{w} \mid D)$ 로 표현 한 것입니다.
\[p(\mathbf{w} \mid D)=\frac{p(D \mid \mathbf{w}) p(\mathbf{w})}{p(D)}\]- $p(\mathbf{w})$ : 데이터를 관측하기 전(prior)에 $\mathbf{w}$에 대한 확률 분포(가정)
- $D = [t_1, \dots, t_2]$ : 관측 데이터
위의 식을 통해 실제 데이터(새로운 관측)을 통해 예측된 $\mathbf{w}$의 확률(likelihood)를 조합하여 사전확률의 불확실성을 갱신한 값($=p(\mathbf{w})$ )를 나타내고 있습니다. 식이 복잡할 경우 다음과 같이 등식이 아닌 비례관계를 사용하여 사후 확률을 나타낼 수 있습니다.
\(\text{사후확률} \propto \text{likelihood} \times \text{사전 확률}\) 더불어, 분모로 포함되는 $p(D)$ 의 경우 확률식에 대한 정규화 요소로 다음과 같이 정의 할 수 있습니다.
\[p(D)=\int p(D \mid \mathbf{w}) p(\mathbf{w}) d \mathbf{w}\]가능도 함수 (likelihood function)
$p(D \mid \mathbf{w})$ 가능도 함수는 베이지안 확률의 관점에서 중요한 의미를 띄고 있습니다. 가능도 함수란 어떤 관측값(데이터)가 관측 되었을 때, 그 관측값이 어떤 확률 분포에서 나왔는지에 대한 확률을 나타냅니다. 즉, 쉽게 말해 지금 얻은 데이터가 이 분포로 부터 나왔을 가능도(확률)을 말합니다.
이 가능도를 계산 하기 위해서 각 데이터 샘플에서 후보 분포에 대한 높이(즉, likelihood 기여도)를 계산해서 다 곱한 것을 이용할 수 있습니다. 이렇게 계할 할 수 있는 모든 후보 분포에 대해서 계산 하여 이를 비교하면 지금 얻은 데이터를 가장 잘 설명할 수 있는 확률 분포를 얻게 됩니다.
이를 수학적으로 표현하면 다음과 같이 표현 할 수 있습니다. 아래와 같이 전체 표본 집합의 PDF 함수를 가능도함수(likelihood function)이라고 합니다.
\[P(x \mid \theta)=\prod_{k=1}^{n} P\left(x_{k} \mid \theta\right)\]최대 가능도(최대 우도법, Maximum likelihood)
최대 우도법이란 관측데이터 $D$를 얻었다고 가정 했을때, $\mathbf{w}$(가중치)로 구성된 어떤 pdf(확률분포) $P(D\mid \mathbf{w})$에서 관측된 표본 데이터 집합 $D$를 통해 $\mathbf{w}$(가중치)의 모수(파라미터)를 추정하는 방법입니다.
즉, 찾고자하는 파라미터 θ에 대하여 다음과 같이 편미분하고 그 값이 0이 되도록 하는 θ를 찾는 과정을 통해 가능도 함수 (likelihood 함수)를 최대화 시켜줄 수 있는 θ를 찾을 수 있습니다.
\(\frac{\partial}{\partial \theta} L(\theta \mid x)=\frac{\partial}{\partial \theta} \log P(x \mid \theta)=\sum_{i=1}^{n} \frac{\partial}{\partial \theta} \log P\left(x_{i} \mid \theta\right)=0\) 머신러닝 문헌에서는 종종 음의 로그 가능도 함수를 오차함수(error function)이라고 일컫습니다. 음의 로그 함수를 단조감소함수(증가하지 않는 경우) 이르모, 가능도의 최댓값을 찾는 것이 오차 함수의 최소값을 찾는 것과 동일한 역활을 수행합니다.